




使用 React 18 增强《纽约时报》的网页性能
作者:Ilya Gurevich
作为《纽约时报》的软件工程师,我们非常重视页面性能、SEO,并尽可能采用最新的技术。所以 React 18 的发布引起了我们的高度关注。我们的网站是基于 React,此次升级不仅能提升性能,还能带来一些令人兴奋的新功能。去年冬天,我们决定在我们的核心新闻网站上采用 React 18。在这个过程中,我们遇到了一些关于 React 和我们自身网站的一些挑战和问题,最终我们实现了非常好性能提升效果。
在深入介绍我们的升级过程之前,让我们先来看看 React 18 带来的一些主要特性和变化:
-
使用并发模式 (Concurrent Mode) 实现更流畅的渲染: React 18 引入了并发模式,这是一种允许同时渲染更新和用户交互的新范式。这意味着动画更流畅,屏幕卡顿和堆叠布局偏移更少,用户体验更快。
-
Automatic Batching 和 Transitions 功能: 为了充分利用并发模式,React 18 在单个渲染周期内自动批处理状态更新,从而优化性能。它通过打破主线程中的任务来实现,这与之前几乎所有任务同步执行的机制有很大不同。引入的新 useTransition hook 还允许开发者确保某些状态在不阻塞 UI 的情况下更新。
-
令人期待的新功能: React 18 为服务器端渲染和通过 React 服务器组件 (React Server Components) 进行流式更新等功能铺平了道路。
性能提升对我们尤为重要,因为它能显著提升我们的 “从交互到下一次绘制”(Interaction to Next Paint, INP)分数。INP 是页面响应性的衡量标准,是 Google 用于搜索结果排名的一套最新核心 Web 指标。SEO 分数对于新闻组织至关重要,提高我们的 INP 分数一直是一个巨大挑战,使得 React 升级成为一个高优先级(且高风险)的任务。
我们的迁移过程
1. 移除已弃用的依赖项
在我们开始迁移之前,我们需要移除与 React 18 不兼容的弃用的 Enzyme 测试库。为此,我们必须手动将所有测试文件迁移到更现代的库 @testing-library/react。在时间投入方面,这可能是整个项目中最耗时的部分。Enzyme 被用于我们代码库中的数百个测试文件,这需要大量的手动操作和数十个 pull request 来完全替换它。我们用了几个月的时间,通过渐进式的 pull request 来完成这一工作。当搞定所有之后,我们感觉自己已经是 @testing-library/react API 的专家。
2. 打好基础
在完成测试文件迁移后,我们可以开始集成 React 18 的工作。为了安全起见,我们首先升级了所有主要依赖项、类型和测试,以符合 React 18,而不实际实现最新功能。这涉及到升级我们代码库中 package.json 文件中的 @types/react、react-test-renderer、react-dom 和 @testing-library 等到最新版本。升级所有主要依赖项也涉及对某些测试和类型定义进行重构,以符合最新版本。
3. 启动引擎
我们开始准备整合 React 18 的新功能。为了将这些功能变为现实,我们需要使用最新的 API:createRoot 和 hydrateRoot。我们在多个 Web 服务器上的多个实例中集成了 React Hydration, 这些服务器之间共享了一组 UI 组件,因此我们尽可能多地启用 React 18 功能非常重要。乍一看,这看起来只是将引用从 ReactDOM.hydrate 更改为 hydrateRoot 这么简单,但真的是这样吗?
意外的挑战
作为开发人员,当你开始 “部署到生产环境” 上时,很容易盲目自信。你的端到端集成和单元测试已经通过,你已经覆盖了各种设备和情况的 QA,并且你正准备上线最新功能。我们在最初将 React 最新版本部署到《纽约时报》网站时,所有人都有这种感觉。初次部署新升级后,我们在一些高流量内容上遇到了一些问题,特别是我们称为 “嵌入式互动” 的内容类型。
将嵌入式互动适应 React 18
在《纽约时报》,我们使用在服务器端渲染的自定义嵌入式互动,通过 dangerouslySetInnerHTML 渲染。这些互动有自己的 HTML、链接和脚本,独立于 React 树运行。这允许编辑和记者在无需修改或重新部署核心基础设施的情况下将一次性、自包含的可视和互动元素注入页面中。
直接来看一个例子如下(脚本标签会在页面打开后立即修改 DOM):
const embeddedInteractiveString = `
<div id="server-test">server</div>
<script>
document.addEventListener("DOMContentLoaded", () => {
const serverTestElement = document.getElementById("server-test");
serverTestElement.textContent = "client";
});
</script>
`;
return <div dangerouslySetInnerHTML={{ __html: embeddedInteractiveString }} />;
在这段代码中,脚本在页面加载后将 “server-test” 元素的内容从 “server” 修改为 “client”。这是因为浏览器渲染的脚本在 React Hydration DOM 之前执行。它本质上是一个“黑盒”,我们相信注入的 HTML 及其脚本会按预期运行。
Hydration 问题
React 18 的引入带来了更严格的 Hydration 不匹配要求。根据新规则,初始浏览器加载和客户端 Hydration 之间的任何 DOM 修改都会触发回退到客户端渲染。在我们的示例中,即使脚本标签在 Hydration 前修改了 “server-test” 元素,一旦发生 Hydration 不匹配,React 会丢弃服务器渲染的内容并回退到客户端渲染,从而使脚本的影响失效。在以前版本的 React 中,即使存在 Hydration 不匹配,React 团队也选择将 DOM 的版本保持在无效状态,而不是完全在客户端重新渲染,这就是我们过去没有遇到任何问题的原因。
实际操作中,这意味着在使用 dangerouslySetInnerHTML 属性在客户端渲染组件时,任何包含 <script> 标签的 HTML 片段由于浏览器安全考虑将不会运行。这意味着由于使用 dangerouslySetInnerHTML 属性发生 Hydration 不匹配重新渲染的任何嵌入式互动将表现得像脚本从未执行过一样。在我们上面的示例中,文本内容将从 “server” 变为 “client”,但在发生 Hydration 不匹配时,它将重新渲染为 “server”。这导致我们的一些嵌入式互动看起来与预期渲染大相径庭。
预期表现:
实际表现:
如何解决?
由于 React 18 对 Hydration 不匹配比 React 16 更敏感,我们有两个选择。第一个是修复网站上所有潜在的 Hydration 不匹配。第二个是适应嵌入式互动,在发生 Hydration 不匹配时让其在客户端重新挂载。这让我们很难搞。因为《纽约时报》发布了数百万篇文章,包含数百个不同组件和成千上万个自定义嵌入式互动。我们当然想要修复所有的 Hydration 不匹配,但如何才能安全地做到这一点呢?
最终,我们决定同时解决这两个问题。
手动提取和执行嵌入式互动脚本
我们知道通过 innerHTML 属性(或在客户端重新渲染期间)添加的脚本标签不会自动运行,因为浏览器的安全考虑。那么我们如何绕过这个问题呢?只有当脚本标签手动附加或替换为 DOM 中的另一个元素的子节点时,脚本才会运行。这意味着,为了正确运行脚本标签,我们必须首先从互动 HTML 中提取并移除它们,然后在组件重新渲染时将它们附加回嵌入式互动 HTML 中的正确位置。
// 此函数用空的占位符替换通用 HTML 中的 script 标签。
// 这 allows us to replace the script tag reference in-place later on client-mount with the actual script.
export const addsPlaceholderScript = (scriptText, id, scriptCounter) => {
let replacementToken = '';
let hoistedText = scriptText;
replacementToken = `<script id="${id}-script-${scriptCounter}"></script>`;
hoistedText = hoistedText.replace('<script', `<script id="${id}-script-${scriptCounter}"`);
return {
replacementToken,
hoistedText,
};
};
// 此函数从互动 HTML 字符串中提取并移除 <script> 标签,
// 并返回一个包含以下内容的对象:
// - `scriptsToRunOnClient`:一个将在客户端加载时运行的脚本文本数组。
// - `scriptlessHtml`:删除了脚本的修改后的 HTML 字符串,带有空的脚本引用。
export const extractAndReplace = (html, id) => {
const SCRIPT_REGEX = /<script[\s\S]*?>[\s\S]*?<\/script>/gi;
let lastMatchAdjustment = 0;
let scriptlessHtml = html;
let match;
const scriptsToRunOnClient = [];
let scriptCounter = 0;
while ((match = SCRIPT_REGEX.exec(html))) {
const [matchText] = match;
if (matchText) {
let hoistedText = matchText;
let replacementToken = '';
({ hoistedText, replacementToken } = addsPlaceholderScript(hoistedText, id, scriptCounter));
scriptCounter += 1;
const start = match.index - lastMatchAdjustment;
const end = match.index + matchText.length - lastMatchAdjustment;
scriptlessHtml = `${scriptlessHtml.substring(
0,
start
)}${replacementToken}${scriptlessHtml.substring(end, scriptlessHtml.length)}`;
scriptsToRunOnClient.push(hoistedText);
lastMatchAdjustment += matchText长度 - replacementToken长度;
}
}
return {
scriptsToRunOnClient,
scriptlessHtml,
};
};
// 在客户端运行脚本
const runScript = (clonedScript) => {
const script = document.getElementById(document.getElementById(`${clonedScript.id}`))
script.parentNode.replaceChild(clonedScript, script);
}
你可能会问,为什么不将脚本保留在服务器上,然后在客户端重新运行它们?其中的一个原因是某些脚本标签会在全局范围内声明变量而不是在函数闭包内。如果你在服务器上预渲染这些脚本标签,然后在客户端重新运行它们,你会遇到因全局变量重复声明而出现的错误,这是不允许的。
这一初步解决方案修复了我们大多数的嵌入式互动。不过,不是每个互动都能与随机顺序的脚本执行兼容。这里我们需要处理一些细微之处:
脚本加载顺序
一些互动脚本在附加回嵌入式互动 HTML 时必须按正确顺序加载。先前的脚本执行策略假设所有 <script> 标签已经在服务器上声明并预渲染。现在我们正在剥离脚本标签并在客户端重新挂载它们,基于这些原则的一些固有逻辑会被破坏。让我们通过一个示例来进行说明。
<script>
const results = document.getElementById("RESULTS_MANIFEST").innerHTML.ELECTION_RESULTS;
// 使用结果进行其他逻辑处理
</script>
<div>
互动 DOM 内容在这里
</div>
<script id="RESULTS_MANIFEST">{"ELECTION_RESULTS": ['result1', 'result2', ....]}</script>
在上述场景中,我们有一个初始脚本,通过 ID 搜索另一个脚本标签,然后根据第二个脚本标签的 innerHTML 进行一些现有逻辑处理。在先前的迭代中,由于脚本标签在服务器上预渲染,因此引用脚本标签没有任何问题,因为脚本标签默认情况下会在 DOM 中可用。
为了最佳互动,脚本执行需要在重新附加到 DOM 时遵循特定顺序。这包含:
- 首先附加包含静态数据的非功能性清单脚本。
- 接下来异步执行带有 src 属性的脚本。
- 最后附加和执行其 innerHTML 中带有原生 JavaScript 的脚本。
这种顺序可以防止脚本在正确加载之前相互引用。
// 解析提供的脚本标签,返回用于排序的优先级。
// 优先级 1:用于 JSON 或其他元数据内容。
// 优先级 2:用于其他原生 JS 或 src 内容
export const getPriority = template => {
let priority;
try {
JSON.parse(template.innerHTML);
priority = 1;
} catch (err) {
priority = 2;
}
return priority;
};
scripts.sort((a, b) => getPriority(a) - getPriority(b));
立竿见影的性能提升
在集成了这些嵌入式互动代码的操作后,我们认为可以安全地再次将 React 18 发布到线上。虽然我们永远无法对将近 40,000 个自定义创建的嵌入式互动进行广泛的 QA,但我们可以依赖一些 graphics 团队经常返回的可重用模板。这让我们能够在我们的 Svelte 或 Adobe Illustrator 基于的嵌入式互动中验证具体行为。长期来看,我们致力于消除所有剩余的 Hydration 不匹配,确保足够稳定。但在短期内,我们准备再次部署到线上。
在发布新功能后(并花了一小时紧张地监测内部警报以防出现任何问题),我们几乎马上就看到了性能的提升。
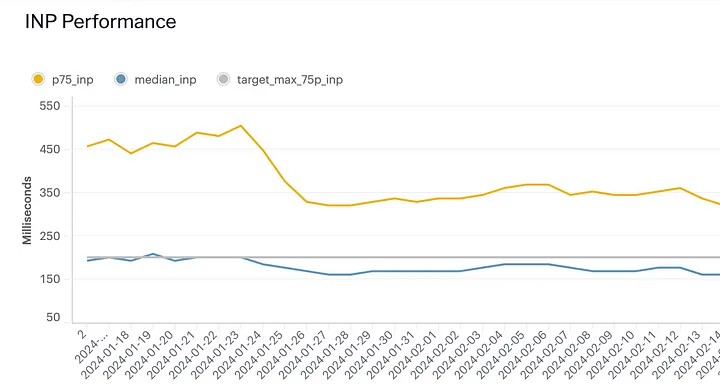
正如你从这张图表中看到的,p75 范围内的 INP 分数下降了大约 30%!
在升级之前,我们最大的挑战之一是新闻网站加载页面时频繁的重新渲染。这导致了糟糕的用户体验(以及糟糕的 INP 分数),特别是用户在尝试与仍在加载的页面交互时。
在 React 18 升级之后,我们的重新渲染次数几乎减半了!
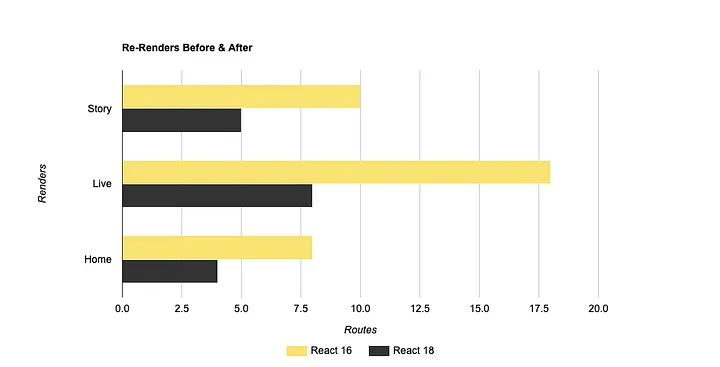
这两个非常明显且重要的改进是 React 18 的自动批处理和并发功能的直接结果。这给了我们一个非常明确和积极的信号,表明我们正在朝着正确的方向前进。
我们的未来计划
React 18 的集成为我们带来了显著的改进,为我们开启了许多以前无法实现的可能性。我们现在专注于探索新功能,例如 “startTransition” 和 “React Server Components” 的潜在优势。我们的核心目标是持续降低我们的 INP 分数,并改善整体功能。然而,我们也意识到关于这些新功能还有一些问题需要解答。目前,我们首要任务是确保我们正在使用的 React 版本的稳定和可靠性。
通过新闻网站的性能提升效果,我们开始对一些其他网站进行升级,因为我们在这些网站上看到了同样的性能提升。我们在 Google 的 INP 评分中不再是 “差”,避免了在 Google 三月截止日期前出现负面的 SEO 影响。我们相信读者正在享受这种更极速的体验。我们的新闻编辑部门继续每天发布有趣的互动内容,而无需再考虑他们的渲染框架。